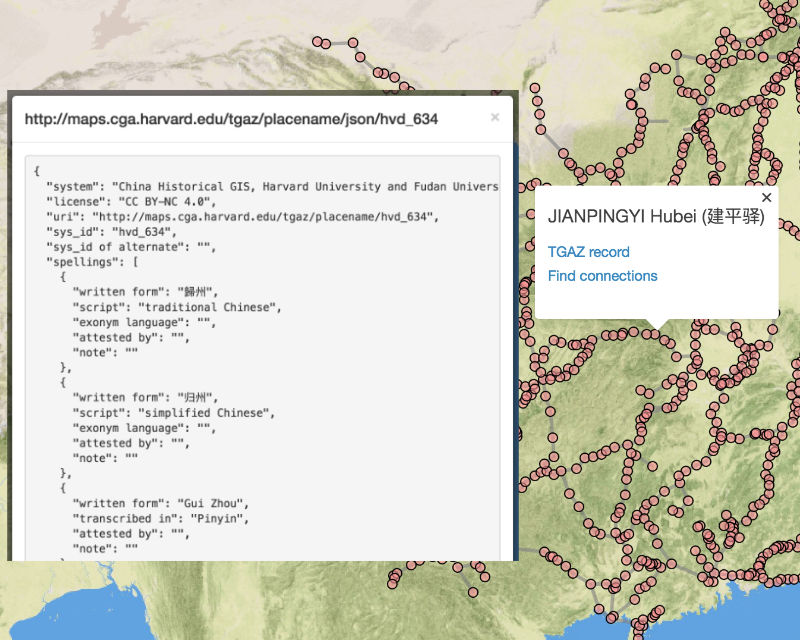
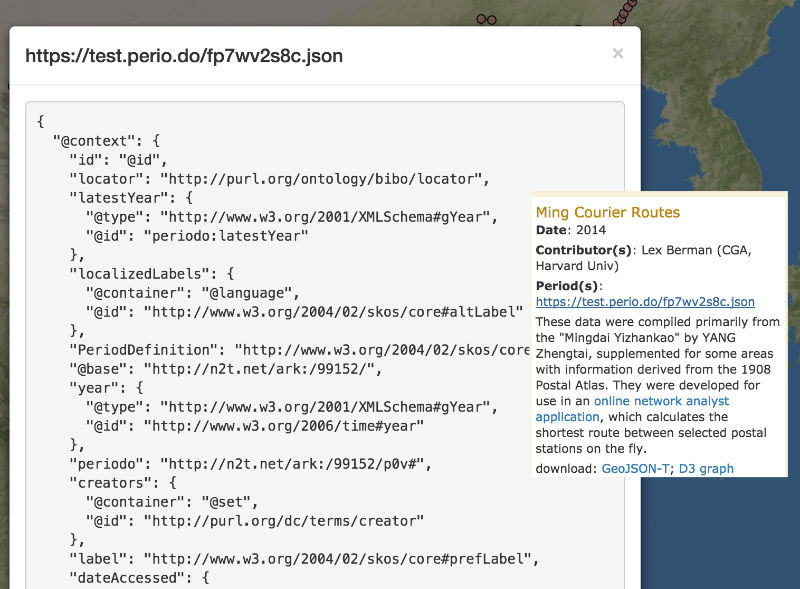
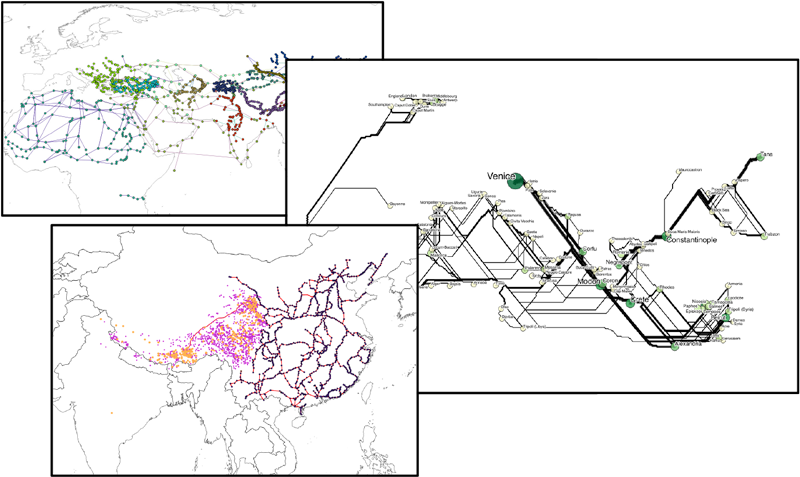
GeoJSON has become a popular standard format for representing geographic features in web mapping applications. It is supported by the key JavaScript libraries Leaflet, Mapbox, OpenLayers, and D3, and to some extent by desktop GIS software (QGIS, ArcMap). GitHub renders valid GeoJSON as simple maps, and web-based utility applications like geojson.io and GeoJSONLint help users create, edit and validate it.
As the name suggests, GeoJSON-T adds time to GeoJSON. Geographic features, defined broadly[1], include events we want to map and analyze (e.g. births, deaths, battles, journeys, publication). For many analyses and mapping tasks, the temporal attributes of geographic features are as important as their geometry. Furthermore, many non-eventive geographic features–settlements, polities, buildings, monuments, earthworks, archaeological finds and so on–have essential temporal attributes.
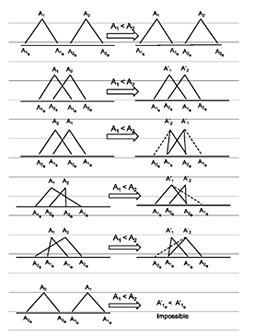
It is hardly controversial that a great many natural and fictional phenomena have a relevant spatial and temporal coverage (cf. Dublin Core), or setting.[2] Shouldn’t the de facto standard for geographic feature data account for time?
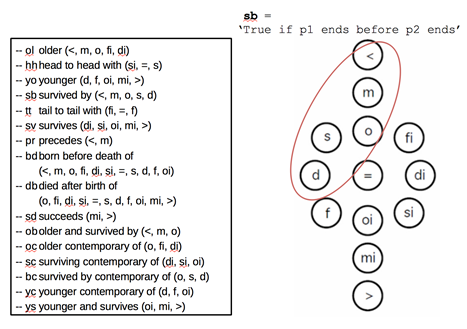
It could be (and has been) argued that time can be added to a GeoJSON feature as a member of its “Properties” element, organized however one sees fit. Certainly true, and many have. At issue is whether there should be a simple accepted standard location and format for temporal information within a GeoJSON Feature. If there were, a) new software, or new versions of existing software, could parse those temporal elements and render them to timeline visualizations[3], and b) data from multiple projects could be linked and analyzed by means of period assertions or computed “temporal topology” (e.g. Allen’s interval algebra[4]: equals, overlaps, before, after, starts, finishes, meets).
How would this work?
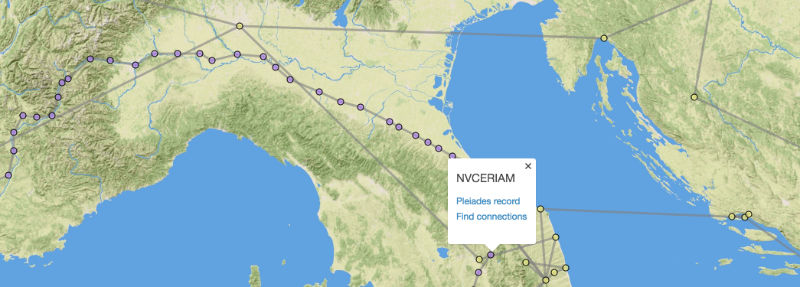
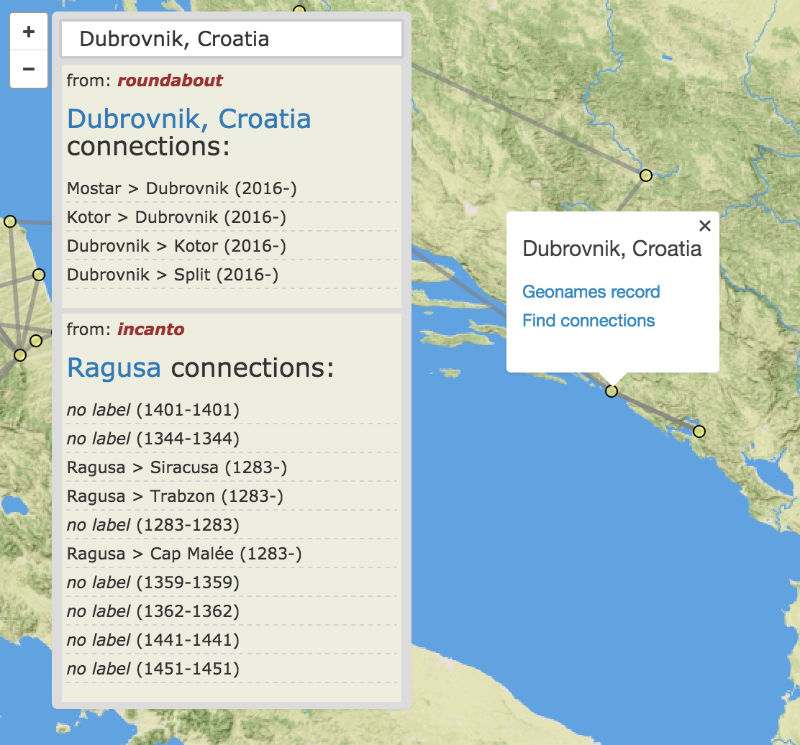
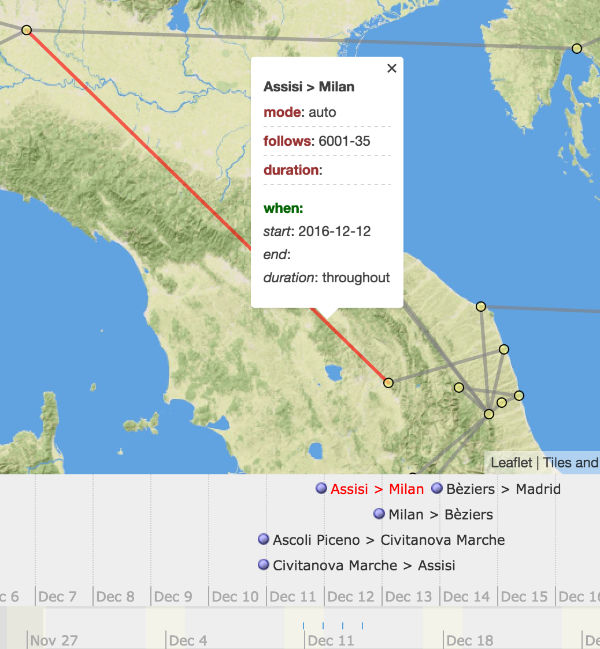
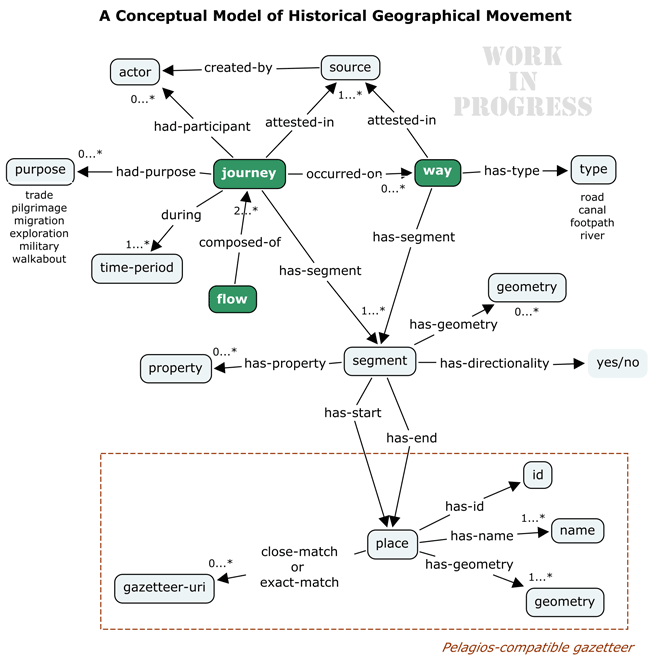
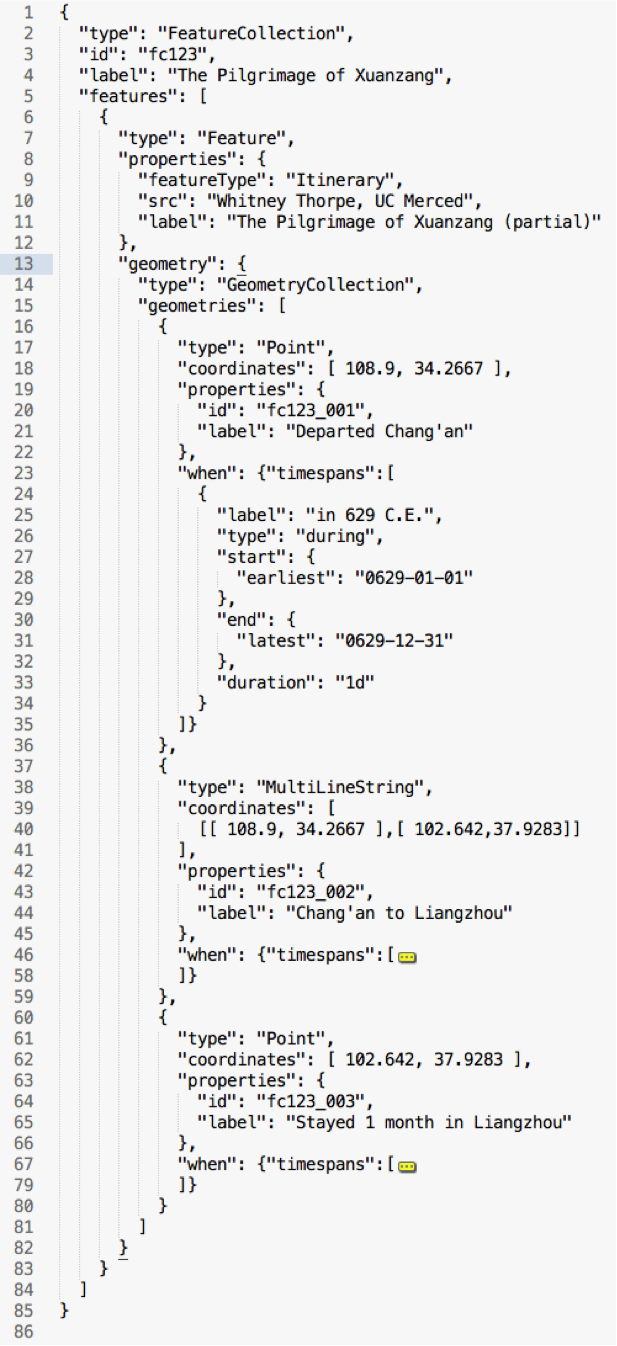
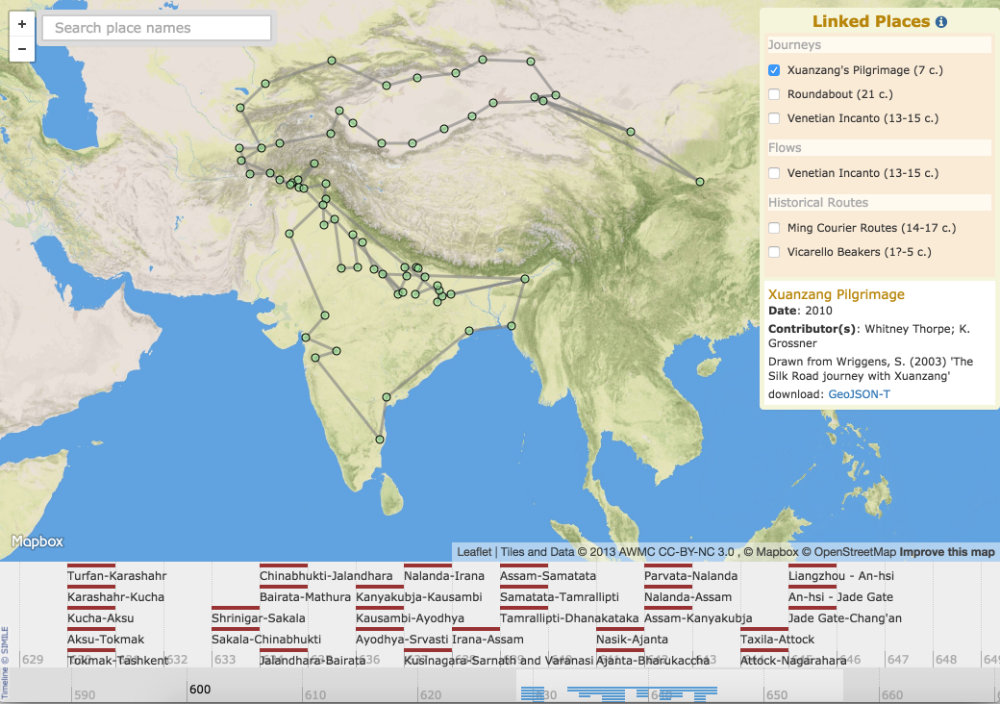
The first conceptual step is a simple matter: wherever a “geometry” element is required in GeoJSON, an optional adjacent (sibling) “when” element is allowed. Existing software supporting GeoJSON would simply ignore these and function normally. New software, or new versions of existing software, would parse them and offer visualization and analytic functionality. In the Linked Pasts demo prototype, I render “when” elements to a timeline using the venerable if outdated Simile Timeline library, linked to the “geometry” elements rendered traditionally to a Leaflet map (Figure 1).
Developing a standard
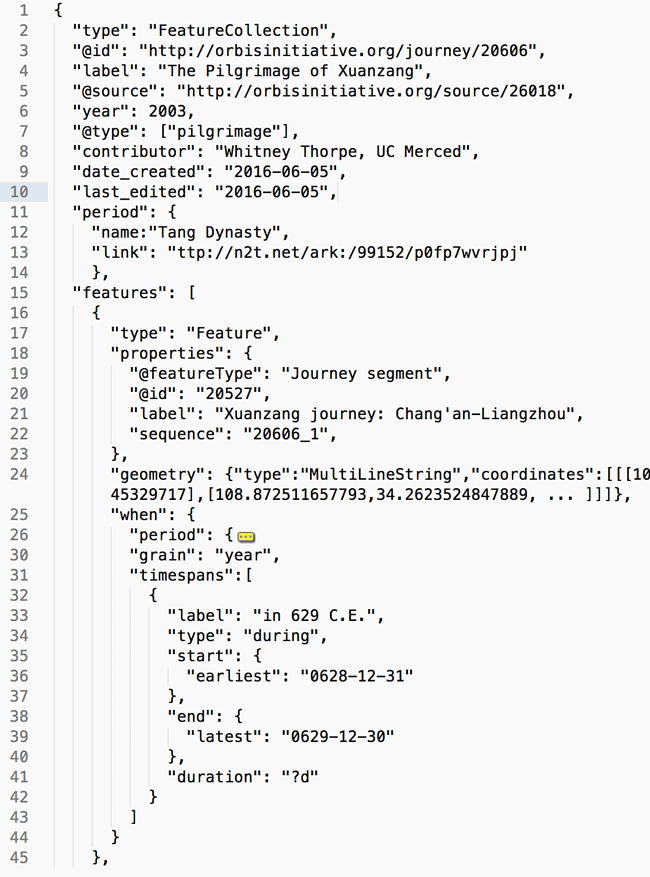
It’s well and good to say, “wherever there’s a ‘geometry’ allow an optional ‘when’,” but the devil is in the details. What is required and allowed in that “when?” I’m not experienced at ringleading standards development; what I’ve done for starters is create a provisional standard for discussion, then made the aforementioned demo app as proof-of-concept. The “when” looks like this:
"when": {
"timespans": [["-323-01-01 ","","","-101-12-31",
"Hellenistic period"]],
"duration": "?",
"periods": [{
"name": "Hellenistic Period",
"period_uri": " http://n2t.net/ark:/99152/p0mn2ndq6bv"
}],
"follows": "<feature or geometry id>",
}
An explanation of each element:
When
Optional. A sibling of “geometry” in a Feature (a), or of “coordinates” in a member of a GeometryCollection (b)
(a)
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"id": "",
"properties": {},
"geometry": {},
"when": {}
}
]
}
(b)
"geometry": {
"type": "GeometryCollection",
"geometries": [
{
"type": "LineString",
"coordinates": [[93.867,40.35],[108.9423,34.26]],
"when": {}
}
]
}
Timespans
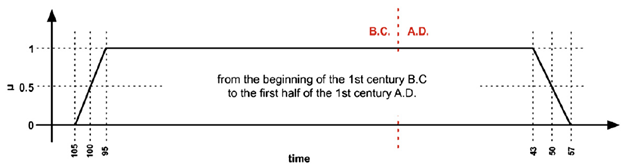
Required. An array of one or more 5-part arrays, the positions of which are Start, Latest Start, Earliest End, End, Label. Of these, only Start is required. The first 4 positions accept any ISO-8601 temporal expression, with the ‘accepted convention’ of a minus sign for BCE years. Label is an optional short text string that would (presumably) appear alongside a visual representation of the timespan.
Duration
Required. A null value indicates the phenomena occurred (or was valid) throughout the feature’s Timespans. If it occurred only for some part of it/them, enter an integer followed by a single letter code for the increment (d=days; m=months; y=years) or a “?” for an unknown duration. For example, a weeklong festival at some unknown time within a year timespan would be indicated as “duration”:”7d”; a birth as (perhaps) “duration”:”1d”
I anticipate timeline visualizations will be find this distinction essential; a birth for example does not occur throughout a year.
Periods
Optional. An array of Period objects defined in an external period gazetteer (e.g. PeriodO, each with a “name” and “period_uri” that can be dereferenced dynamically.
Follows
Optional. If the Feature or GeometryCollection member is in a meaningful sequence, enter the internal identifier of the element it follows here. Software indicating order or directionality visually or in lists will make use of these values if present.
Next Steps
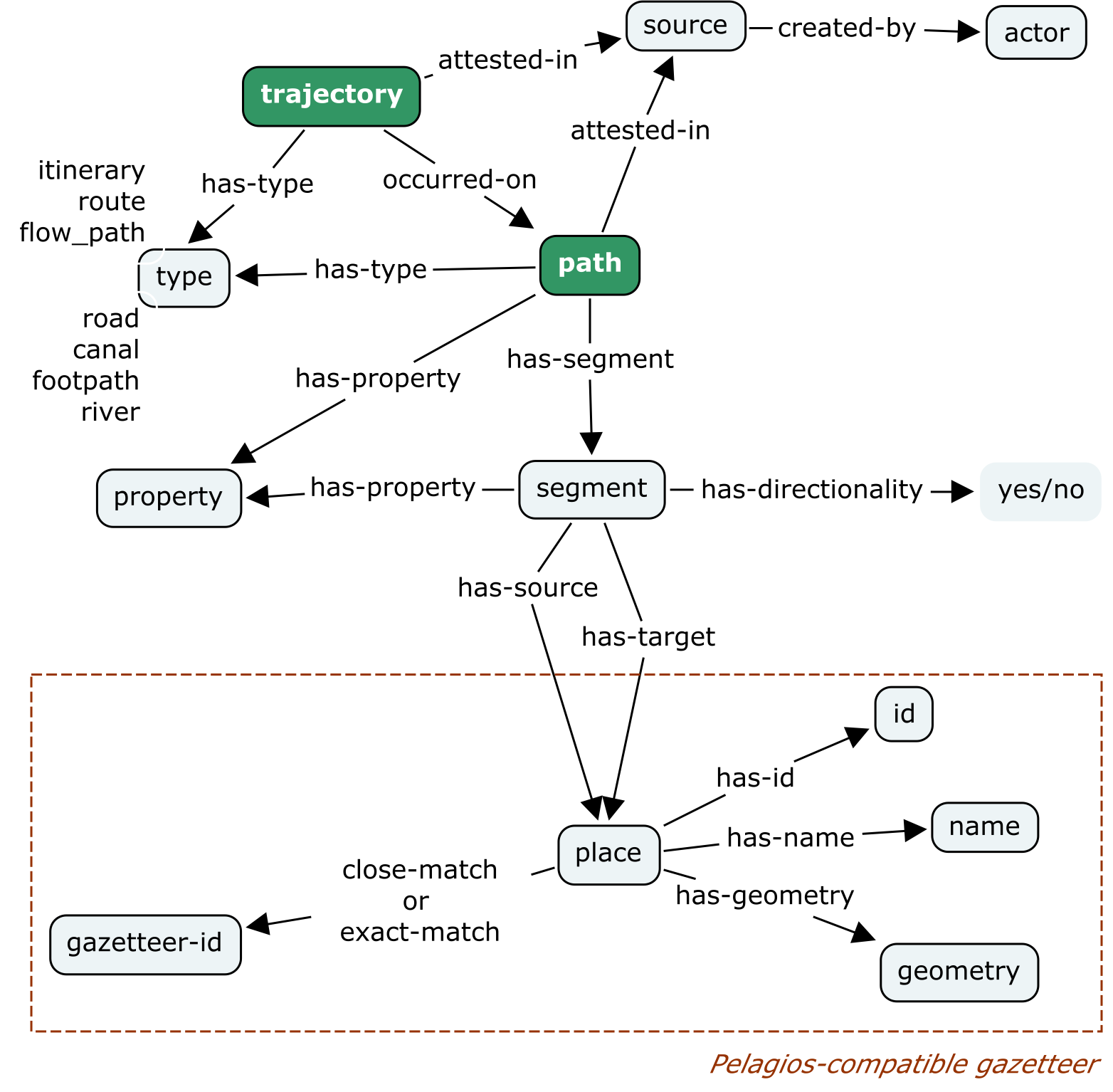
I’d like to move the development of GeoJSON-T into a more formal process, but perhaps that should follow more informal discussion. A more detailed explanation of GeoJSON-T and its implementation for data about historical movement — journeys, flows and named routes — appears in the Topotime GitHub repo.
Please let me know your views on how we might proceed, by twitter (@kgeographer) or as a GitHub issue or preferably both. In the meantime, I will continue converting exemplar datasets into the provisional format outlined here, and developing software and utility scripts to manage, display, and even analyze it.
[1] A GIScience-ish definition for geographic features: “Phenomena on or near the earth surface for which location and other spatial attributes are integral for understanding and analysis.”
[2] An ontology design pattern for Setting was proposed in Grossner, K., Janowicz, K. and Keßler, C. (2016). The Place of Linked Data for Historical Gazetteers. In R. Mostern, H. Southall, and M.L. Berman (Eds.). Placing Names: Enriching and Integrating Gazetteers. Bloomington: Indiana University Press.
[3] As I have begun demonstrating with Linked Places work (http://topotime.org/linkedplaces)
[4] https://en.wikipedia.org/wiki/Allen’s_interval_algebra