
When my colleague Elijah Meeks recently tweeted about the possibility of a temporal topology data standard (“topotime” as he called it), my reaction was: Fantastic! Maybe the time has arrived, so to speak, for a proper Period datatype in relational databases like PostgreSQL, to meet the needs of historical scholarship—a comprehensive means for qualitative reasoning about historical time. And while we’re at it, how about a generic Period ontology design pattern that could be used in any RDFS/OWL representations? It’s not that a start towards topotime hasn’t been made, only that we can advance things considerably if we as a community get specific about general requirements. Hmm…specifics about generality.
Our standard options in relational databases at the moment are to use one or more ISO 8601 date fields or integer fields to cobble together something that meets our immediate requirements: for example, either a single DATE or YEAR, or START and END fields in a form of either yyyy‑mm‑dd, or nnnn. We can then use the operators <, >, and = to readily compute the 13 relations of Allen’s interval algebra (before, meets, overlaps, starts, during, finishes-and their inverses-plus equals). In RDF-world, we find the Allen relations are present in CIDOC-CRM.
What more could we (humanist representers of time and temporality) possibly want? That question was the topic of a short talk I gave in a recent panel at the DH2013 in Lincoln, NE. How about a single Period field for starters—a compound date?
In fact, an existing extension for PostgreSQL written by Jeff Davis provides this (https://github.com/jeff-davis/PostgreSQL-Temporal), and I’ve used it several times. Davis provides, along with operators for standard Allen relations, several more to get finer grain, e.g. to differentiate between before (overlaps-or-left-of) and strictly-before. There are also numerous functions for computing relationships in SQL statements. A Period is entered as a date array that looks like this:
[ (yyyy-mm-dd), (yyyy-mm-dd) ]
The begin and end dates (and parts thereof) are still accessible using first(period) and last(period) functions, and these can be used in concert with PostgreSQL’s built-in date-part and interval functions to calculate periods of interest on the fly. For example, in a recent project we converted birth and death dates to Period lifetimes and calculated contemporaries as individuals who were adults ( >= 17 ) at the same time: overlaps( (first(lifetime)::date + 17 years, last(lifetime)), (1832-01-01, 1874-11-23)).
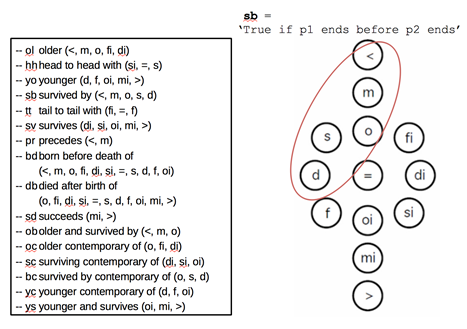
If you happen to be using PostgreSQL, this helps with many use cases, but we can and should go much further. I made a baby step in the course of dissertation research, by writing a series of Postgres functions to perform some minimal computation over Christian Freksa’s temporal conceptual neighborhoods (sets of 13 semi‑intervals) using the Period datatype (Fig. 2). These neighborhoods are sets of semi-interval relations corresponding to some common (and not so common) reasoning tasks. For example, survived-by merges less‑than, meets, overlaps(left), starts, and during. Freksa’s algebra has many more elements which I didn’t use, but should be considered going forward.
Now, what of uncertainty in its many forms—the vague, probabilistic, and contested data we routinely encounter? The many classes of uncertainty have been outlined in a fairly exhaustive taxonomy a decade ago by historical geographer Brandon Plewe (2002), and that work should be helpful in future modeling efforts. If an event began “most likely in late Spring, 1832 (Jones 2013),” when should its representation appear in a dynamic interactive visualization having a granularity of months? When it appears in a time-filtering application, how should it differ from an event that began in “April, 1832 (Smith 2012)?”
Application logic to do something about such cases would need an underlying temporal entity having a probability (0 – 1) and/or some kind of ‘confidence’ weight. If we’re talking about the span of the event, it’s a period bounded not by instants (dates) but by periods, each with an author and probability/confidence value.
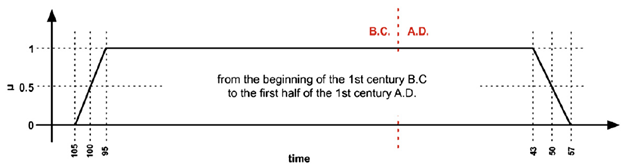
In fact, some very nice research to formalize such temporal objects using periods bounded by periods has been done in the context of historical/heritage applications. Members of the FinnOnto group (Kaupinnen et al 2010) have developed a formal representation and algebra for fuzzy historical intervals (Fig. 3).
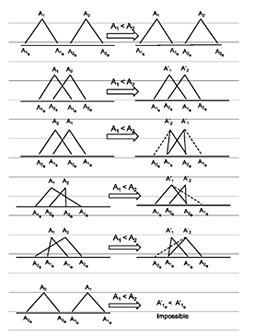
In the realm of semantic (ontological) representations, Holmen and Ore (2009) have developed a database system based on the event-centric CIDOC-CRM that includes an algebra (Fig. 4) and temporal analyzer module to reduce fuzziness and aid in the creation of event sequences as “Stored Story Objects.” Like the previous work, period starts and ends are represented as intervals.
Ceri Binding (2009) developed a CIDOC-CRM based representation of multiple attestations of historical periods and their extents for the archaeological project, STARS.
All of the work I’ve mentioned seems to me compatible in fundamental respects. I believe that as a community of interest can we can collaboratively develop a few shared resources that would be very helpful for many research projects. For example, a Linked Data repository of historical periods along the lines of what Pleiades/Pelagios does for places in the Classical Mediterranean. Lex Berman of the Harvard Center for Geographical Analysis has given this a lot of thought and done some prototype work, as have others. What is the right venue for making this happen?
Another concrete goal is extending the Period datatype for PostgreSQL to allow a probability or confidence term for each bounding period. Once that is worked out, someone might even port it to ArcGIS. Yeah.
NOTE: These and related topics are among those to be addressed by a proposed new GeoHumanities SIG for the Alliance of Digital Humanities Organizations (ADHO) I’m co-instigating with Kathy Weimer of Texas A & M. Further word on that within a week or so.
Cited works
Binding, C. (2009). Implementing archaeological time periods using CIDOC CRM and SKOS. CAA 2009 Proceedings (http://hypermedia.research.southwales.ac.uk/media/files/documents/2010-06-09/ESWC2010_binding_paper.pdf)
Freksa, C. (1992). Temporal reasoning based on semi-intervals, Artificial Intelligence 54, 199-227
(http://cindy.informatik.uni-bremen.de/cosy/staff/freksa/publications/TemReBaSeIn92.pdf)
Kauppinen, T., Mantegari, G., Paakkarinen, P., Kuittinen, H., Hyvonen, E., Bandini, S. (2010). Determining relevance of imprecise temporal intervals for cultural heritage information retrieval. International Journal of Human-Computer Studies 68 (2010) 549–560 (http://kauppinen.net/tomi/temporal-relevance-ijhcs2010.pdf)
Holmen, J., and Ore, C. (2009). Deducing event chronology in a cultural heritage documentation system. In CAA 2009 Proceedings (http://www.edd.uio.no/artiklar/arkeologi/holmen_ore_caa2009.pdf)
Plewe, B. (2002). The Nature of Uncertainty in Historical Geographic Information. Transactions in GIS, 6(4): 431-456. (http://dusk.geo.orst.edu/buffgis/TGIS_uncertainty.pdf)
Plewe, B. (2003). Representing Datum-level Uncertainty in Historical GIS. Cartography and Geographic Information Science, 30(4):319-334