I’ve recently been co-developing with colleague Elijah Meeks something called Topotime, which at this stage is experimental software for rendering timelines and doing some computational reasoning about historical timespans, such as calculating overlap. The first adjective we use to describe this work is pragmatic, because we felt we had thought hard enough about time versus temporality for digital humanities work [1], and built enough temporal data models and timelines, that we should begin some concrete steps to “operationalize” [2] our views and personal wishlists in some working software. The results to date have just been publicly released on GitHub, and we hope other will participate in its further development. Elements of the Topotime data model and software are novel (we think) but it is built around a couple of common and successful design patterns.
I’ve recently been co-developing with colleague Elijah Meeks something called Topotime, which at this stage is experimental software for rendering timelines and doing some computational reasoning about historical timespans, such as calculating overlap. The first adjective we use to describe this work is pragmatic, because we felt we had thought hard enough about time versus temporality for digital humanities work [1], and built enough temporal data models and timelines, that we should begin some concrete steps to “operationalize” [2] our views and personal wishlists in some working software. The results to date have just been publicly released on GitHub, and we hope other will participate in its further development. Elements of the Topotime data model and software are novel (we think) but it is built around a couple of common and successful design patterns.
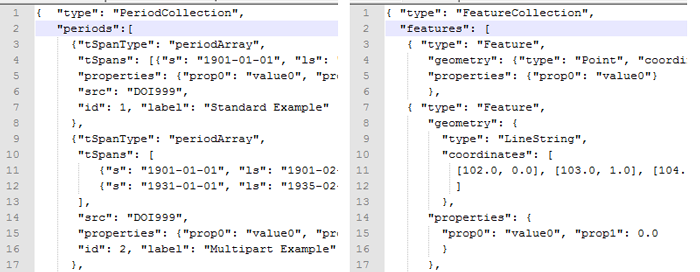
First, Topotime models Periods in PeriodCollections, much as GeoJSON models Features in FeatureCollections. GeoJSON Features have a typed geometry and unlimited number of user-defined properties. Topotime Periods have typed timespans (tSpan) and unlimited user-defined properties. Topotime can be written as a JSON object, just as GeoJSON is. I find the symmetry between representation requirements for spatial things and temporal things astonishing, although it would probably not surprise physicists. For starters, both have names, metrical representations (geometries, even), and are usefully typed. The close relationship between places and periods will be a refrain on this blog.
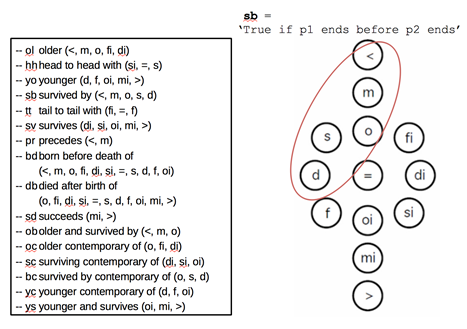
The second borrowed pattern is representing the uncertain boundaries of intervals as intervals themselves, not “instants” (there aren’t very many instants in historiography). The result is a quad of start (s), latest start (ls), earliest end (ee), and end (e). The first and third of these can be stated in natural language as “not before,” and the second and fourth as “not after.” This pattern appears in Simile Timeline and in several scholarly works I cited in an earlier blog post.

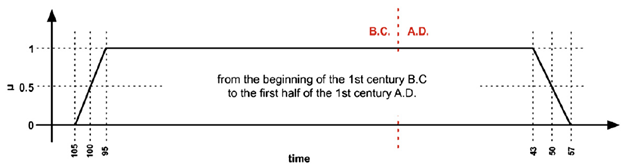
Topotime extends that pattern to allow any of these to be qualified as “about” or “approximately” (~) some day, month or year. It also parses an elaboration of the starting and ending spans (sls and eee respectively). The result is a function returning a probability y for any time x. The area under the function’s curve, although not a useful number in and of itself, can be used to good effect in computing overlap with other period or event timespans, and with query areas (as discussed in this short paper [PDF], and earlier demonstrated by Kauppinen et al [3]). The Topotime model also permits specifying intermittent, multi-part timespans which can be cyclical or irregular.
Meeting of minds (and conceptualizations)
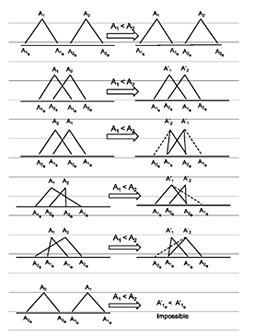
Topotime’s name, courtesy of Elijah, stems from our wish to capture certain topological relations between periods (their timespans actually). We can know a period or event began after another and not know when that is exactly but wish to represent and reason about that adjacency. Similarly, we may know two events (lives, e.g.) overlapped, but have only minimal information about their starts and ends.
As it turned out, tackling that issue led to a more involved data model. Its hard to know where to put the bounds on development projects, due to the EAGER principle we live by here: Everything’s A Graph and Everything’s Related. Both Elijah and I have been working at event data models for multiple projects for several years, and this was an opportunity to operationalize some of our individual perspectives, which differ but seem to have important overlaps as well.
These are a couple of the agreements and how they’ve appeared in Topotime so far:
- There are temporal things, which include events, historical periods, and lifespans of things, people and groups (e.g. nations). They all share some representation requirements, so in software we can make a super-class for them, potentially specializing distinctive differences in sub-classes later. But for the time being every temporal thing is a Period, for lack of a better all-encompassing term, and we don’t do anything different for events, lifespans and historical periods. If you add an attribute like class or css_class to the generic periods you can make them render distinctively in a timeline app.
- Periods have meaningful relationships to other Periods, some of which are non-topological. For this, Topotime recognizes a relations[ ] array of simple subject-predicate-object triples. This will be written as JSON-LD soon, and therefore be Semantic Web compatible. That is, although relationships between the timespans of two events are metrical, measured, and possibly incidental (they overlap, abut, are disjoint, etc.), relationships between periods are a different thing. The most basic is compositional, or mereological ( Peter Simons’ Parts: A study in ontology is fascinating, and short). Events are composed of or contained by other events. We use a part_of relation for this.
Other relationships researchers might wish to encode include caused, required, led_to, etc., none of which we deal with yet. At minimum we might like to visualize our understandings and arguments about these in timeline interfaces (perhaps along the lines of Nowiskie and Drucker’s PlaySpace 2003 [1]). Quite possibly, we can find further interesting ways to compute over them, but they first must find their way into data models.
[1] Although not as hard as Bethany Nowiskie and Johanna Drucker! I only recently came across a trove of their interesting work theorizing time v. temporality, and building out pilots for novel timeline applications for digital humanities. For example, the Temporal Modelling Project and PlaySpace 2003 [screenshots]
[2] A term with plenty of history, but recently the subject of a really nice Stanford Lit Lab pamphlet by Franco Moretti.
[3] Tomi Kauppinen, Glauco Mantegari, Panu Paakkarinen, Heini Kuittinen, Eero Hyvönen, and Stefania Bandini. (2010). Determining Relevance of Imprecise Temporal Intervals for Cultural Heritage Information Retrieval. International Journal of Human-Computer Studies, Volume 68, Issue 9, pp. 549-560 , Elsevier. Preprint PDF